Try our code
Paper
 |
Lian Xu, Wanli Ouyang, Mohammed Bennamoun, Farid Boussaid, Dan Xu
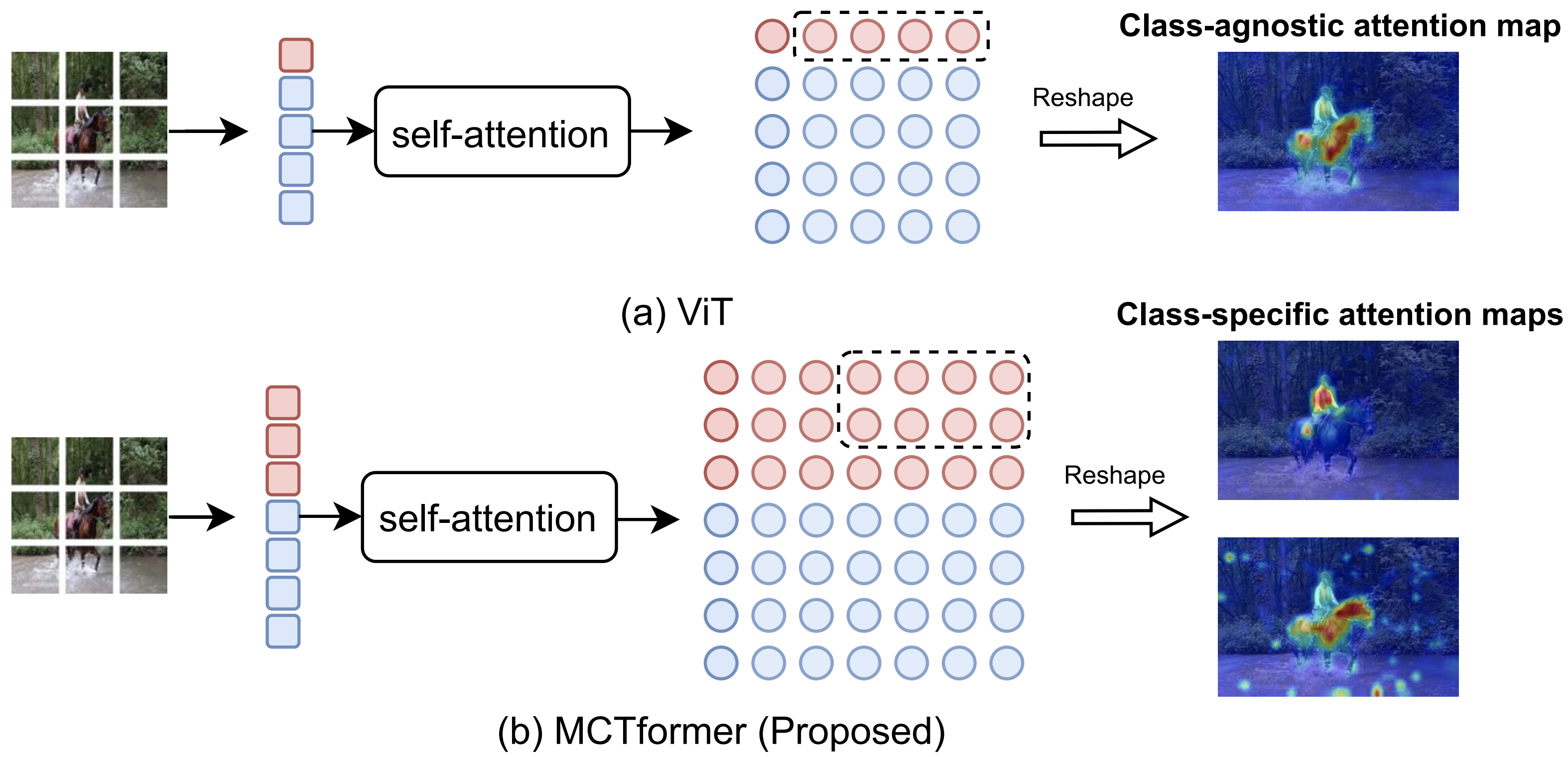
Multi-class Token Transformer for Weakly Supervised Semantic Segmentation
CVPR, 2022 (Paper)
|
Experiments
Here we show comparison with the state-of-the-art WSSS methods. Please see the paper for more details.
|
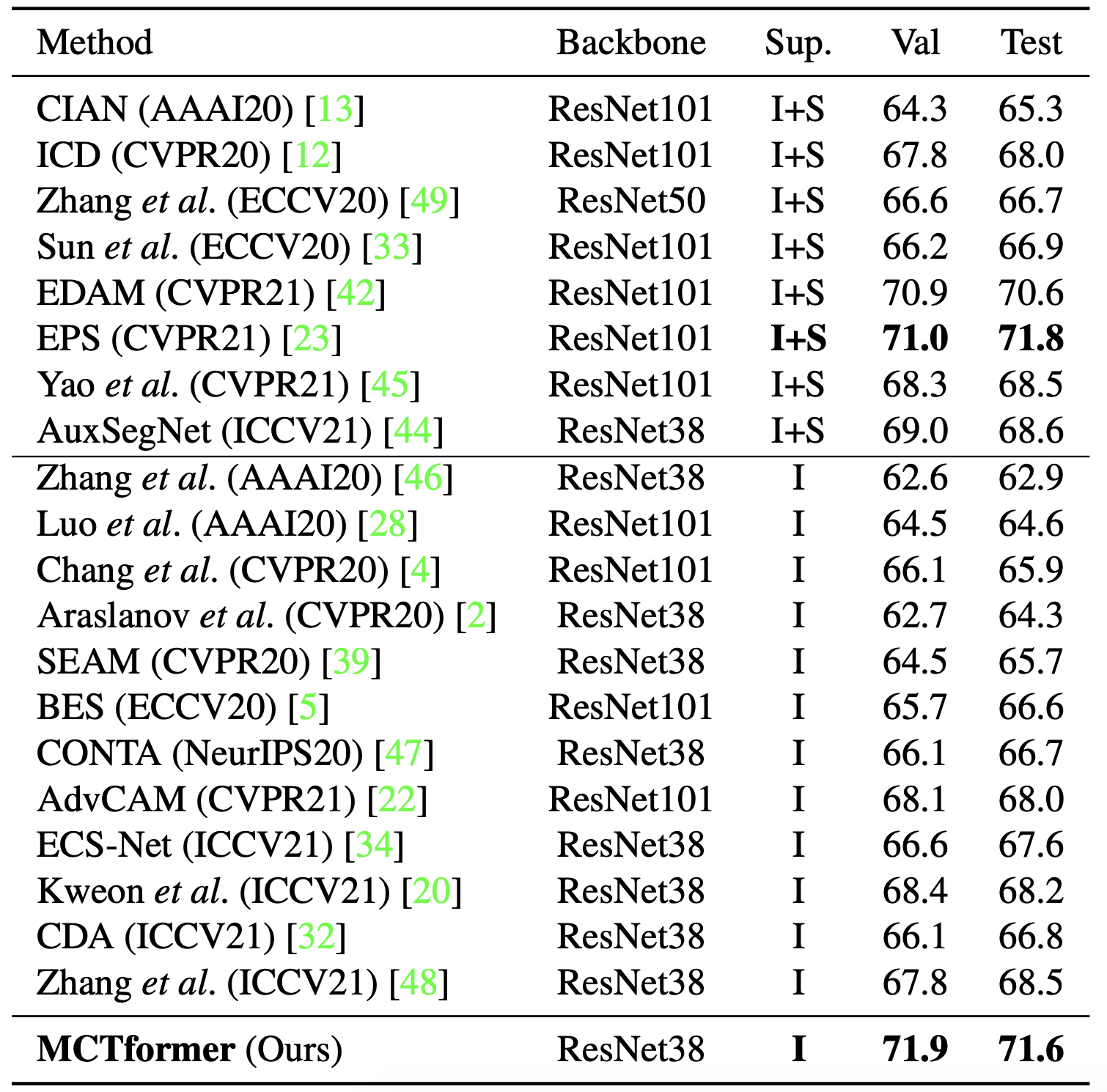
Table 1. Segmentation performance comparison of WSSS methods in terms of mIoU (%) on the PASCAL VOC 2012 val and test sets using different segmentation backbones. Sup.: supervision. I: image-level ground-truth labels. S: off-the-shelf saliency maps.
|
|
|
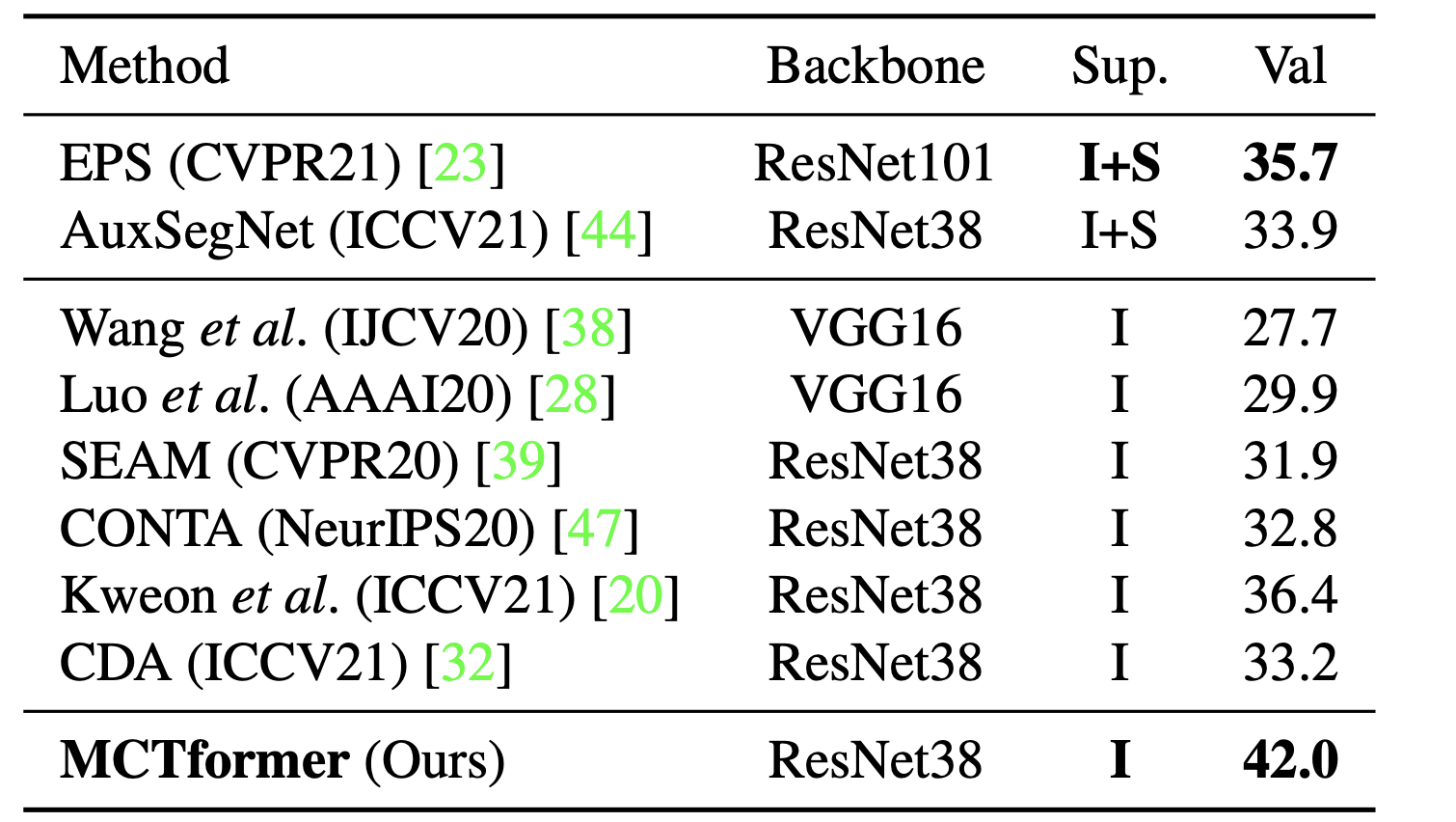
Table 2. Segmentation performance comparison of WSSS methods in terms of mIoU (%) on the MS COCO validation set.
|
|

|
Figure 2. Visualization of the generated class-specific localization maps by MCTformer on the PASCAL VOC train set.
|
Acknowledgements
This research is supported in part by Australian Research Council Grant DP210101682, DP210102674, DP200103223, Australian Medical Research Future Fund MRFAI000085, CRC-P Smart Material Recovery Facility (SMRF) - Curby Soft Plastics, the Early Career Scheme of the Research Grants Council (RGC) of the Hong Kong SAR under grant No.
26202321 and HKUST Startup Fund No. R9253.
|
|